Шифр цезаря на python (руководство по шифрованию текста)
Содержание:
- Универсальный декодер
- Решение
- Определение кодировки
- Шифр Виженера
- Цифровые шифры
- Почему шифрование слабое?
- литература
- Шифр Цезаря в Python на примере английского алфавита
- Шифрование методом публичного ключа
- Создание таблицы поиска
- Стеганография
- Типы шифров
- Частотный анализ
- Функция chr()
- О программе
- Алгоритм шифрования ADFGX
Универсальный декодер
Сервис отлично справляется с кириллицей. Очень популярен среди юзеров рунета. Если вы выбрали его для работы, то необходимо сделать копию текста, нуждающегося в декодировании и вставить в специальное поле. Следует размещать отрывок так, чтобы уже на первой строчке были непонятные знаки.
Если вы хотите, чтобы ресурс автоматически смог раскодировать, придется отметить это в списке выбора. Но можно выполнять и ручную настройку, указав выбранный тип. Итоги можете найти в разделе «Результат». Вот только тут есть определенные ограничения. К примеру, если в поле вставить отрывок более 100 Кб, софт не обработает его, так что нужно будет выбирать кусочки.

Решение
Теперь, когда мы определили наши две функции, давайте сначала воспользуемся функцией шифрования, чтобы зашифровать секретное сообщение, которое друг передает через текстовое сообщение своему другу.
Обратите внимание, что все, кроме знаков препинания и пробелов, зашифровано. Теперь давайте посмотрим на шифрованный текст, который полковник Ник Фьюри посылал на свой пейджер: “Mr xli gsyrx sj 7, 6, 5 – Ezirkivw Ewwiqfpi!”
Теперь давайте посмотрим на шифрованный текст, который полковник Ник Фьюри посылал на свой пейджер: “Mr xli gsyrx sj 7, 6, 5 – Ezirkivw Ewwiqfpi!”.
Это оказывается шифротекст Цезаря, и, к счастью, ключ к этому шифру у нас в руках.
Давайте посмотрим, сможем ли мы обнаружить скрытое послание.
Отличная работа, Мстители!
Определение кодировки
Есть несколько способов определения:
- В Ворде во время открытия документа: если есть отличия от СР1251, редактор предлагает выбирать одну из самых подходящих кодировок. Оценить, насколько они аналогичны, можно по превью текстового образца;
- В утилите KWrite. Сюда загружаете объект с расширением .txt и используете настройки в меню «Кодирование»;
- Открываете объект в обозревателе Mozilla Firefox. При правильном отображении в разделе «Вид» ищите кодировку. Нужный вариант – тот, возле которого установлен флажок. Если все отображается с ошибками, проверяете различные варианты в меню «Дополнительно»;
- Пользователи Unix могут воспользоваться приложением Enca.
С помощью предложенных инструментов вы можете быстро и легко раскодировать текст онлайн. Если у вас мало знаний, воспользуйтесь утилитами с простым меню и функционалом.
Шифр Виженера
Данный шифр на порядок более устойчив к взлому, чем моноалфавитные, хотя представляет собой шифр простой замены текста. Однако благодаря устойчивому алгоритму долгое время считался невозможным для взлома. Первые его упоминания относятся к 16-му веку. Виженер (французский дипломат) ошибочно считается его изобретателем. Чтобы лучше разобраться, о чем идет речь, рассмотрим таблицу Виженера (квадрат Виженера, tabula recta) для русского языка.

Приступим к шифрованию фразы «Касперович смеется». Но, чтобы шифрование удалось, нужно ключевое слово — пусть им будет «пароль». Теперь начнем шифрование. Для этого запишем ключ столько раз, чтобы количество букв из него соответствовало количеству букв в шифруемой фразе, путем повтора ключа или обрезания:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |
| Фраза: | К | А | С | П | Е | Р | О | В | И | Ч | С | М | Е | Е | Т | С | Я |
| Ключ | П | А | Р | О | Л | Ь | П | А | Р | О | Л | Ь | П | А | Р | О | Л |
Теперь по таблице Виженера, как по координатной плоскости, ищем ячейку, которая является пересечением пар букв, и получаем: К + П = Ъ, А + А = Б, С + Р = В и т. д.
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | 15 | 16 | 17 | |
| Шифр: | Ъ | Б | В | Ю | С | Н | Ю | Г | Щ | Ж | Э | Й | Х | Ж | Г | А | Л |
Получаем, что «касперович смеется» = «ъбвюснюгщж эйхжгал».
Взломать шифр Виженера так сложно, потому что для работы частотного анализа необходимо знать длину ключевого слова. Поэтому взлом заключается в том, чтобы наугад бросать длину ключевого слова и пытаться взломать засекреченное послание.
Следует также упомянуть, что помимо абсолютно случайного ключа может быть использована совершенно разная таблица Виженера. В данном случае квадрат Виженера состоит из построчно записанного русского алфавита со смещением на единицу. Что отсылает нас к шифру ROT1. И точно так же, как и в шифре Цезаря, смещение может быть любым. Более того, порядок букв не должен быть алфавитным. В данном случае сама таблица может быть ключом, не зная которую невозможно будет прочесть сообщение, даже зная ключ.
Цифровые шифры
В отличие от шифровки текста алфавитом и символами, здесь используются цифры. Рассказываем о способах и о том, как расшифровать цифровой код.
Двоичный код
Текстовые данные вполне можно хранить и передавать в двоичном коде. В этом случае по таблице символов (чаще всего ASCII) каждое простое число из предыдущего шага сопоставляется с буквой: 01100001 = 97 = «a», 01100010 = 98 = «b», etc
При этом важно соблюдение регистра
Расшифруйте следующее сообщение, в котором использована кириллица:
Шифр A1Z26
Это простая подстановка, где каждая буква заменена её порядковым номером в алфавите. Только нижний регистр.
Попробуйте определить, что здесь написано:
Шифрование публичным ключом
Алгоритм шифрования, применяющийся сегодня буквально во всех компьютерных системах. Есть два ключа: открытый и секретный. Открытый ключ — это большое число, имеющее только два делителя, помимо единицы и самого себя. Эти два делителя являются секретным ключом, и при перемножении дают публичный ключ. Например, публичный ключ — это 1961, а секретный — 37 и 53.
Открытый ключ используется, чтобы зашифровать сообщение, а секретный — чтобы расшифровать.
Как-то RSA выделила 1000 $ в качестве приза тому, кто найдет два пятидесятизначных делителя числа:
Почему шифрование слабое?
Как бы ни был прост в понимании и применении шифр Цезаря, он облегчает любому взлом дешифровки без особых усилий.
Шифр Цезаря – это метод подстановочного шифрования, при котором мы заменяем каждый символ в тексте некоторым фиксированным символом.
Если кто-то обнаружит регулярность и закономерность появления определенных символов в шифротексте, он быстро определит, что для шифрования текста был использован шифр Цезаря.
Если убедиться, что для шифрования текста использовалась техника шифра Цезаря, то восстановить оригинальный текст без ключа будет проще простого.
Простой алгоритм Brute Force вычисляет оригинальный текст за ограниченное время.
Атака методом перебора
Взлом шифротекста с помощью шифра Цезаря – это просто перебор всех возможных ключей.
Это осуществимо, потому что может существовать только ограниченное количество ключей, способных генерировать уникальный шифротекст.
Например, если в шифротексте зашифрованы все строчные буквы, то все, что нам нужно сделать, это запустить шаг расшифровки со значениями ключа от 0 до 25.
Даже если бы пользователь предоставил ключ выше 25, он выдал бы шифротекст, равный одному из шифротекстов, сгенерированных с ключами от 0 до 25.
Давайте рассмотрим шифротекст, в котором зашифрованы все строчные символы, и посмотрим, сможем ли мы извлечь из него разумный шифротекст с помощью атаки “методом перебора”.
У нас есть текст:
Сначала определим функцию расшифровки, которая принимает шифротекст и ключ и расшифровывает все его строчные буквы.
Теперь у нас есть наш текст, но мы не знаем ключа, т.е. значения смещения. Давайте напишем атаку методом перебора, которая пробует все ключи от 0 до 25 и выводит каждую из расшифрованных строк:
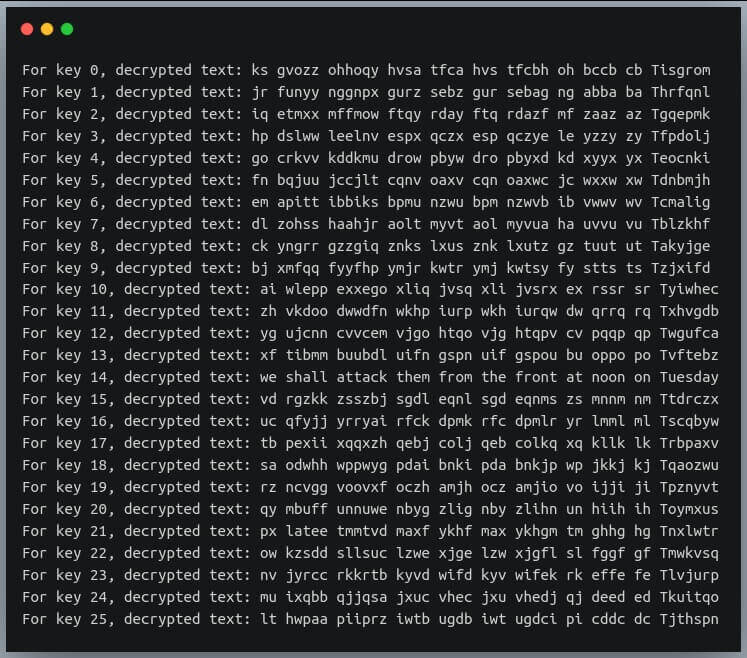
В выводе перечислены все строки, которые могут быть получены в результате расшифровки.
Если вы внимательно посмотрите, строка с ключом 14 является правильным английским высказыванием и поэтому является правильным выбором.

Теперь вы знаете, как взломать шифр с помощью шифра Цезаря.
Мы могли бы использовать другие более сильные варианты шифра Цезаря, например, с использованием нескольких сдвигов (шифр Виженера), но даже в этих случаях определенные злоумышленники могут легко расшифровать правильную расшифровку.
Поэтому алгоритм шифрования Цезаря относительно слабее современных алгоритмов шифрования.
литература
- Фридрих Л. Бауэр : Расшифрованные секреты. Методы и положения криптологии. 3-е, переработанное и дополненное издание. Springer, Berlin et al., 2000, ISBN 3-540-67931-6 .
- Линда А. Бертрам, Гюнтер ван Дубл и др. (Ред.): Номенклатура — Энциклопедия современной криптографии и интернет-безопасности. От AutoCrypt и экспоненциального шифрования до ключей с нулевым разглашением. Книги по запросу, Norderstedt 2019, ISBN 978-3746-06668-4 .
- Albrecht Beutelspacher Kryptologie — Введение в науку о шифровании, сокрытии и сокрытии без какой-либо секретности, но не без лживого мошенничества, представленное для пользы и удовольствия широкой публики . Vieweg & Teubner, 9-е обновленное издание, Брауншвейг 2009 г., ISBN 978-3-8348-0253-8 .
- Клаус Бейрер (ред.): Совершенно секретно! Мир зашифрованного общения . Braus Verlag, Гейдельберг, 1999.
- Йоханнес Бухманн : Введение в криптографию . Springer, 4-е расширенное издание, Берлин 2008 г., ISBN 978-3-540-74451-1 .
- Майкл Миллер: Симметричные методы шифрования — проектирование, разработка и криптоанализ классических и современных шифров . Teubner, Wiesbaden 2003, ISBN 3-519-02399-7 .
- Клаус Шме : Взломщики кода против создателей кода — Увлекательная история шифрования . W3L-Verlag, 2-е издание, Herdecke 2008, ISBN 978-3-937137-89-6 .
- Брюс Шнайер : Прикладная криптография . Протоколы, алгоритмы и исходный код в C. Pearson Studium, Мюнхен 2006, ISBN 3-8273-7228-3 .
- Саймон Сингх : Секретные сообщения . Карл Хансер Верлаг, Мюнхен 2000, ISBN 3-446-19873-3 .
- Фред Б. Риксон: коды, шифры и другие секретные языки — от египетских иероглифов до компьютерной криптологии . Könemann, Кельн 2000, ISBN 3-8290-3888-7 .
Шифр Цезаря в Python на примере английского алфавита
Прежде чем мы погрузимся в определение функций для процесса шифрования и расшифровки шифра Цезаря в Python, мы сначала рассмотрим две важные функции, которые мы будем использовать в процессе – chr() и ord().
Важно понимать, что алфавит в том виде, в котором мы его знаем, хранится в памяти компьютера по-разному. Сам компьютер не понимает алфавит английского языка или другие символы
Сам компьютер не понимает алфавит английского языка или другие символы.
Каждый из этих символов представлен в памяти компьютера с помощью числа, называемого кодом символов ASCII (или его расширением – Unicode), который представляет собой 8-битное число и кодирует почти все символы, цифры и пунктуацию.
Например, заглавная буква “А” представлена числом 65, “В” – 66 и так далее. Аналогично, представление строчных символов начинается с числа 97.
Когда возникла необходимость включить больше символов и знаков из других языков, 8 бит оказалось недостаточно, поэтому был принят новый стандарт – Unicode, который представляет все используемые в мире символы с помощью 16 бит.
ASCII является подмножеством Unicode, поэтому кодировка символов ASCII остается такой же в Unicode. Это означает, что ‘A’ все равно будет представлено с помощью числа 65 в Юникоде.
Обратите внимание, что специальные символы, такие как пробел ” “, табуляция “\t”, новая строка “\N” и т.д., также представлены в памяти своим Юникодом. Мы рассмотрим две встроенные функции Python, которые используются для поиска представления символа в Unicode и наоборот
Мы рассмотрим две встроенные функции Python, которые используются для поиска представления символа в Unicode и наоборот.
Шифрование методом публичного ключа
Самый популярный из алгоритмов шифрования, который используется повсеместно в технике и компьютерных системах. Его суть заключается, как правило, в наличии двух ключей, один из которых передается публично, а второй является секретным (приватным). Открытый ключ используется для шифровки сообщения, а секретный — для дешифровки.

В роли открытого ключа чаще всего выступает очень большое число, у которого существует только два делителя, не считая единицы и самого числа. Вместе эти два делителя образуют секретный ключ.
Рассмотрим простой пример. Пусть публичным ключом будет 905. Его делителями являются числа 1, 5, 181 и 905. Тогда секретным ключом будет, например, число 5*181. Вы скажете слишком просто? А что если в роли публичного числа будет число с 60 знаками? Математически сложно вычислить делители большого числа.
В качестве более живого примера представьте, что вы снимаете деньги в банкомате. При считывании карточки личные данные зашифровываются определенным открытым ключом, а на стороне банка происходит расшифровка информации секретным ключом. И этот открытый ключ можно менять для каждой операции. А способов быстро найти делители ключа при его перехвате — нет.
Создание таблицы поиска
Строковый модуль Python предоставляет простой способ не только создать таблицу поиска, но и перевести любую новую строку на основе этой таблицы.
Рассмотрим пример, когда мы хотим создать таблицу первых пяти строчных букв и их индексов в алфавите.
Затем мы используем эту таблицу для перевода строки, в которой все символы “a”, “b”, “c”, “d” и “e” заменены на “0”, “1”, “2”, “3” и “4” соответственно, а остальные символы не тронуты.
Для создания таблицы мы будем использовать функцию maketrans() модуля str.
Этот метод принимает в качестве первого параметра строку символов, для которых требуется перевод, и другой параметр такой же длины, содержащий сопоставленные символы для каждого символа первой строки.
Давайте создадим таблицу для простого примера.
Таблица представляет собой словарь Python, в котором в качестве ключей указаны значения символов Unicode, а в качестве значений – их соответствующие отображения.
Теперь, когда у нас есть готовая таблица, мы можем переводить строки любой длины с помощью этой таблицы.
К счастью, за перевод отвечает другая функция модуля str, называемая translate.
Давайте используем этот метод для преобразования нашего текста с помощью нашей таблицы.
Как вы можете видеть, каждый экземпляр первых пяти строчных букв был заменен их относительными индексами.
Теперь мы используем ту же технику для создания таблицы поиска для шифра Цезаря на основе предоставленного ключа.
Стеганография
Стеганография старше кодирования и шифрования. Это искусство появилось очень давно. Оно буквально означает «скрытое письмо» или «тайнопись». Хоть стеганография не совсем соответствует определениям кода или шифра, но она предназначена для сокрытия информации от чужих глаз.
Стеганография является простейшим шифром. Типичными ее примерами являются проглоченные записки, покрытые ваксой, или сообщение на бритой голове, которое скрывается под выросшими волосами. Ярчайшим примером стеганографии является способ, описанный во множестве английских (и не только) детективных книг, когда сообщения передаются через газету, где малозаметным образом помечены буквы.
Главным минусом стеганографии является то, что внимательный посторонний человек может ее заметить. Поэтому, чтобы секретное послание не было легко читаемым, совместно со стеганографией используются методы шифрования и кодирования.
Типы шифров
История криптографии началась тысячи лет назад. Криптография использует множество различных типов шифрования. Ранние алгоритмы выполнялись вручную и существенно отличаются от современных алгоритмов , которые обычно выполняются машиной.
Исторические шифры
Исторические ручные и бумажные шифры, использовавшиеся в прошлом, иногда называют классическими шифрами . Они включают:
-
Замещающий шифр : единицы открытого текста заменяются зашифрованным текстом (например, шифр Цезаря и одноразовый блокнот )
- Полиалфавитный шифр замещения : шифр замещения с использованием нескольких алфавитов замещения (например, шифр Виженера и машина Enigma )
- Полиграфический шифр замены : единица замены представляет собой последовательность из двух или более букв, а не только одну (например, шифр Playfair )
- Шифр транспозиции : шифротекст представляет собой перестановку открытого текста (например, шифр ограждения рельсов )
Исторические шифры обычно не используются в качестве отдельного метода шифрования, потому что их довольно легко взломать. Многие классические шифры, за исключением одноразового блокнота, могут быть взломаны с использованием грубой силы .
Современные шифры
Современные шифры более безопасны, чем классические шифры, и предназначены для противодействия широкому спектру атак. Злоумышленник не должен быть в состоянии найти ключ, используемый в современном шифре, даже если он знает какое-либо количество открытого текста и соответствующего зашифрованного текста. Современные методы шифрования можно разделить на следующие категории:
- Частный ключ криптография ( алгоритм симметричного ключа ): тот же ключ используется для шифрования и дешифрования
- Криптография с открытым ключом ( алгоритм асимметричного ключа ): для шифрования и дешифрования используются два разных ключа.
В алгоритме с симметричным ключом (например, DES и AES ) отправитель и получатель должны иметь общий ключ, настроенный заранее и хранящийся в секрете от всех других сторон; отправитель использует этот ключ для шифрования, а получатель использует тот же ключ для дешифрования. В алгоритме с асимметричным ключом (например, RSA ) есть два отдельных ключа: открытый ключ публикуется и позволяет любому отправителю выполнять шифрование, в то время как закрытый ключ хранится в секрете для получателя и позволяет только ему выполнять правильное дешифрование.
Шифры с симметричным ключом можно разделить на блочные и потоковые . Блочные шифры работают с группами битов фиксированной длины, называемыми блоками, с неизменным преобразованием. Потоковые шифры шифруют цифры открытого текста по одной в непрерывном потоке данных, и преобразование последовательных цифр изменяется в процессе шифрования.
Частотный анализ
Простые шифры
Частотный анализ использует гипотезу о том, что символы или последовательности символов в тексте имеют некоторое вероятностное распределение, которое сохраняется при шифровании и дешифровании.
Этот метод один из самых простых и позволяет атаковать шифры простой замены, в которых символы в сообщении заменяются на другие согласно некоторому простому правилу соответствия.
Однако такой метод совершенно не работает, например, на шифрах перестановки. В них буквы или последовательности в сообщении просто меняются местами, но их количество всегда остается постоянным, как в анаграммах, поэтому ломаются все методы, основанные на вычислении частот появления символов.
Для полиалфавитных шифров — шифров, в которых циклически применяются простые шифры замены — подсчет символов так же не будет эффективен, поскольку для кодировки каждого символа используется разный алфавит. Число алфавитов и их распределение так же неизвестно.
Шифр Виженера
Один из наиболее известных примеров полиалфавитных шифров — шифр Виженера. Он довольно прост в понимании и построении, однако после его создания еще 300 лет не находилось способа взлома этого шифра.
Пусть исходный текст это: МИНДАЛЬВАНГОГ
-
Составляется таблица шифров Цезаря по числу букв в используемом алфавите. Так, в русском алфавите 33 буквы. Значит, таблица Виженера (квадрат Виженера) будет размером 33х33, каждая i-ая строчка в ней будет представлять собой алфавит, смещенный на i символов.
-
Выбирается ключевое слово. Например, МАСЛО. Символы в ключевом слове повторяются, пока длина не достигнет длины шифруемого текста: МАСЛОМАСЛОМАС.
-
Символы зашифрованного текста определяются по квадрату Виженера: столбец соответствует символу в исходном тексте, а строка — символу в ключе. Зашифрованное сообщение: ЩЙЯРПШЭФМЬРПХ.

Этот шифр действительно труднее взломать, однако выделяющиеся особенности у него все же есть. На выходе все же не получается добиться равномерного распределения символов (чего хотелось бы в идеале), а значит потенциальный злоумышленник может найти взаимосвязь между зашифрованным сообщением и ключом. Главная проблема в шифре Виженера — это повторение ключа.
Взлом этого шифра разбивается на два этапа:
-
Поиск длины ключа. Постепенно берутся различные образцы из текста: сначала сам текст, потом текст из каждой второй буквы, потом из каждой третьей и так далее. В некоторый момент можно будет отвергнуть гипотезу о равномерном распределении букв в таком тексте — тогда длина ключа считается найденной.
-
Взлом нескольких шифров Цезаря, которые уже легко взламываются.
Поиск длины ключа — самая нетривиальная здесь часть. Введем индекс совпадений сообщения m:
где n — количество символов в алфавите и
p_i — частота появления i-го символа в сообщении. Эмпирически были найдены индексы совпадений для текстов на разных языков. Оказывается, что индекс совпадений для абсолютно случайного текста гораздо ниже, чем для осмысленного текста. С помощью этой эвристики и находится длина ключа.
Другой вариант — применить критерий хи-квадрат для проверки гипотезы о распределении букв в сообщении. Тексты, получаемые выкидыванием некоторых символов, все равно остаются выборкой из соответствующего распределения. Тогда в критерии хи-квадрат вероятности появления символов можно выбрать используя частотные таблицы языка.
Функция chr()
Точно так же, как при преобразовании символа в его числовой Юникод с помощью метода ord(), мы делаем обратное, то есть находим символ, представленный числом, с помощью метода chr().
Метод chr() принимает число, представляющее Unicode символа, и возвращает фактический символ, соответствующий числовому коду.
Давайте сначала рассмотрим несколько примеров:
Обратите внимание, что немецкая буква Ü также представлена в Юникоде числом 360. Мы можем применить процедуру цепочки (ord, затем chr), чтобы восстановить исходный символ
Мы можем применить процедуру цепочки (ord, затем chr), чтобы восстановить исходный символ.
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
-
Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.. Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.
Алгоритм шифрования ADFGX
Это самый известный шифр Первой мировой войны, используемый немцами. Свое имя шифр получил потому, что алгоритм шифрования приводил все шифрограммы к чередованию этих букв. Выбор самих же букв был определен их удобством при передаче по телеграфным линиям. Каждая буква в шифре представляется двумя. Рассмотрим более интересную версию квадрата ADFGX, которая включает цифры и называется ADFGVX.
| A | D | F | G | V | X | |
| A | J | Q | A | 5 | H | D |
| D | 2 | E | R | V | 9 | Z |
| F | 8 | Y | I | N | K | V |
| G | U | P | B | F | 6 | O |
| V | 4 | G | X | S | 3 | T |
| X | W | L | Q | 7 | C |
Алгоритм составления квадрата ADFGX следующий:
- Берем случайные n букв для обозначения столбцов и строк.
- Строим матрицу N x N.
- Вписываем в матрицу алфавит, цифры, знаки, случайным образом разбросанные по ячейкам.
Составим аналогичный квадрат для русского языка. Например, создадим квадрат АБВГД:
| А | Б | В | Г | Д | |
| А | Е/Е | Н | Ь/Ъ | А | И/Й |
| Б | Ч | В/Ф | Г/К | З | Д |
| В | Ш/Щ | Б | Л | Х | Я |
| Г | Р | М | О | Ю | П |
| Д | Ж | Т | Ц | Ы | У |
Данная матрица выглядит странно, так как ряд ячеек содержит по две буквы. Это допустимо, смысл послания при этом не теряется. Его легко можно восстановить. Зашифруем фразу «Компактный шифр» при помощи данной таблицы:
| 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 | 14 | |
| Фраза | К | О | М | П | А | К | Т | Н | Ы | Й | Ш | И | Ф | Р |
| Шифр | бв | гв | гб | гд | аг | бв | дб | аб | дг | ад | ва | ад | бб | га |
Таким образом, итоговое зашифрованное послание выглядит так: «бвгвгбгдагбвдбабдгвдваадббга». Разумеется, немцы проводили подобную строку еще через несколько шифров. И в итоге получалось очень устойчивое к взлому шифрованное послание.
